¶ Проблемы
- «Распух лог в MS SQL»,
- «Сильно увеличился LDF»,
- «Разрастается log, что делать?»,
- «Журнал занял все свободное место на диске»,
- и многое, многое другое.
¶ Почему растет LOG в MS SQL ?
В этой статье я не буду рассыпать терминами и сложными понятиями гуру специалиста DBA, нет!
Большинство не делает бэкапов журналов транзакций, так как не понимает зависимостей (связей), между их созданием и размерами самого журнала (*ldf).
Собственно цель данной статьи, максимально понятно, на простом языке, объяснить и закрыть раз и навсегда проблему растущего лога в MS SQL!
¶ Почему растет LOG в MS SQL ?

Приступим…
Кратко пройдемся по основам, чтоб даже новички быстро смогли уловить суть и не потеряться в терминах.
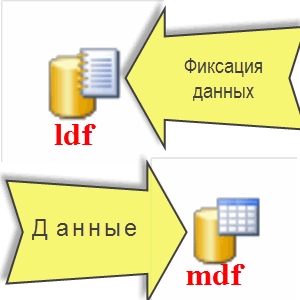
Файл *LDF он же и есть наш журнал транзакций!
¶ Что там хранится?
Каждая база данных SQL Server имеет журнал транзакций, в котором фиксируются все транзакции и производимые ими в базе изменения.
Журнал транзакций — это важная составляющая базы данных. Если система даст сбой, этот журнал поможет вам вернуть базу данных в согласованное состояние.
Если говорить еще проще, благодаря бэкапу ЖТР есть возможность восстановить базу фактически на любой момент времени (вплоть до нужной секунды)!
При этом следует понимать, что никаких по факту данных из 1С в прямом смысле этого слова в журнале нет!
Все данные пишутся в файл *mdf, а вот фиксация этих действий пишется в *ldf, по каждому действию (транзакции), что происходит у Вас в 1С. Все что делают пользователи в 1С, фиксируется в журнале транзакций, только сам факт (фиксация) произошедших событий в базе, а не сами данные.
¶ Почему растет LOG в MS SQL ?
Собственно отсюда и название «Журнал транзакций».
Конечно на практике все сложнее, но в упрощенном для понимания виде все именно так.
Почему растет лог файл в MS SQL (*ldf) ?
Конечно, если учитывать что каждое действие сделанное пользователем в 1С фиксируется в журнале транзакций, то он просто не может не расти! И здесь также стоит отметить, что не только действие пользователя влияет на рост журнала, но и различные регламентные задачи (фоновые различные процессы), особенно сильно заметен рост, когда происходит в базе 1С реструктуризация. Собственно при обновлении конфигурации также можем замечать “взрывной” рост журнала транзакций.
К слову мы только что ответили на частый вопрос: «Вот у меня лог не разрастался» в базе «А», а в базе «Б» растет очень быстро».
Конечно если с базой «Б» пользователи работают интенсивно или различные фоновые, регламентные задачи (их много), безусловно, он будет расти быстрее, такова физика работы «MS SQL»!
¶ Почему растет LOG в MS SQL ?
MS SQL всегда (в “полной” модели восстановления) будет пытаться зафиксировать, фактически все действия в базе. И журнал будет расти до тех пор, пока мы не сделаем его бэкап, этим мы и «усекаем» его!
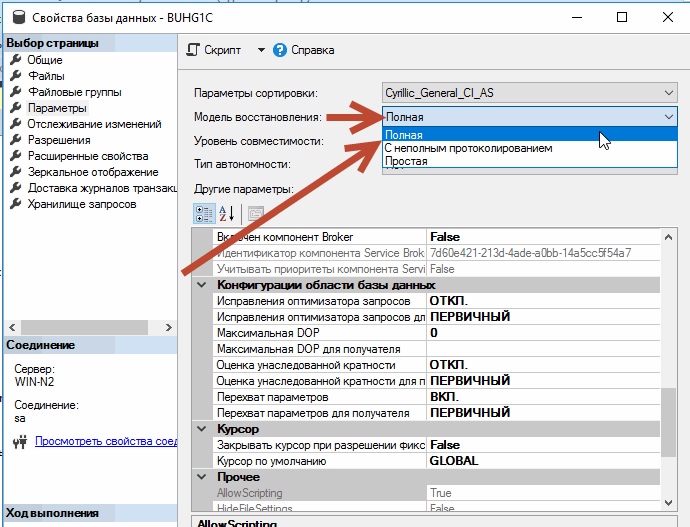
¶ «Простая» и «полная» модель восстановления
Да, «полная» модель восстановления подразумевает, что в журнал будем писать «По максимуму» все возможное. Все что сможет записать MS SQL, он туда запишет. Исключения конечно есть. К примеру, когда свободное место закончилось на диске или есть ограничения на сам лог (если установили). Есть и другие причины, но мы сейчас не об этом.
¶ Почему растет LOG в MS SQL ?
Нам важно понимать одно: «Полная» модель = «Полный» лог! А значит, есть возможность не терять данные, при необходимости восстановится на любой момент времени (фактически до секунды), а выполнив бэкап еще и «заключительного фрагмента журнала» и вообще ничего не потерять!
На сайте Microsoft можно найти информацию о том, что единственная «рабочая» модель, предназначенная для реальной работы, есть только «Полная» модель восстановления! Так как в работе недопустимо терять данные, а это гарантированно произойдет в «Простой» модели восстановления, если случится “сбой”.
«Простая» модель восстановления может использоваться для тестирования, разработки, для временного переключения (Обязательно! С предварительным бэкапом базы и лога). К примеру, только на время реструктуризации ее можно включить, а потом обратно вернуть в «Полную» модель. Есть и другие случаи, когда мы только временно переключаем режим с «Полной в Простой» Но работаем всегда в “полной” модели восстановления!
В “простой” модели мы никак не можем восстановиться (в случаи чего) на интересующий нас момент времени. Только на тот момент, когда сделан либо «полный» бэкап, либо «полный» + «разностный»!
Вывод:
Только в «полной» модели мы должны работать! Она не зря «по умолчанию» в MS SQL!
¶ «Активная» и «Неактивная» часть журнала
Сперва дадим ответ на вопрос: «Что происходит в момент создания бэкапа ЖТР ?»
Чтоб разобраться в этом вопросе, нам нужно понимать, что журнал транзакций может быть «условно разделен» на две части: «Активная» и «Неактивная» часть журнала.
«Активная» – содержит изменения, которые были сделаны в базе, но еще не зафиксированы на диске.
«Неактивная» – изменения уже зафиксированы на диске, следовательно, можно усекать неактивную часть журнала (делать бэкап), вплоть до его активной части!
Неактивная часть журнала транзакций содержит информацию о завершенных транзакциях и не используется сервером SQL Server в процессе восстановления данных. Вместо увеличения размера файла журнала транзакций SQL Server будет повторно использовать освободившееся пространство.
¶ Почему растет LOG в MS SQL ?
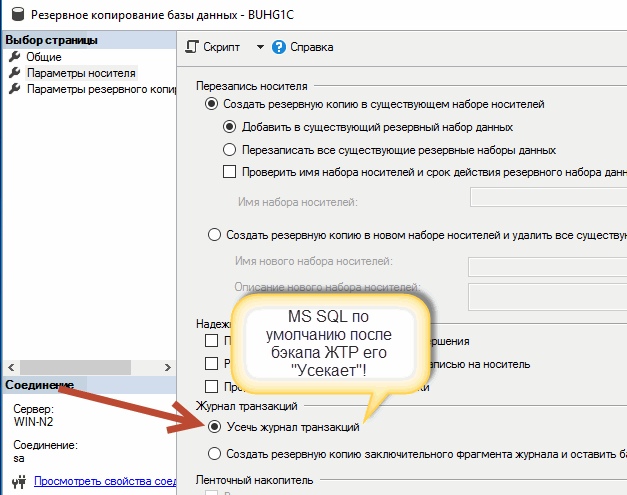
И вот в момент, когда мы создаем бэкап журналов транзакций, мы тем самым «усекаем» его «неактивную» часть (точнее это делает сам MS SQL), вплоть до начала его активной части!
При этом вначале всегда происходит его бэкап, а только после уже «усечение», как на рисунке выше.
Бэкап журналов нужно делать довольно часто (раз на 30-60 мин), особенно если с базой активно работают пользователи, он может вырасти довольно быстро, и конечно без автоматизации этого процесса не обойтись!
Также мы можем сделать и бэкап «заключительного фрагмента журнала транзакций», если нужно восстановить базу на самый последний момент времени. В таком случаи мы также усекаем журнал (ту часть, что есть на момент создания самого заключительного фрагмента журнала).
¶ Почему растет LOG в MS SQL ?
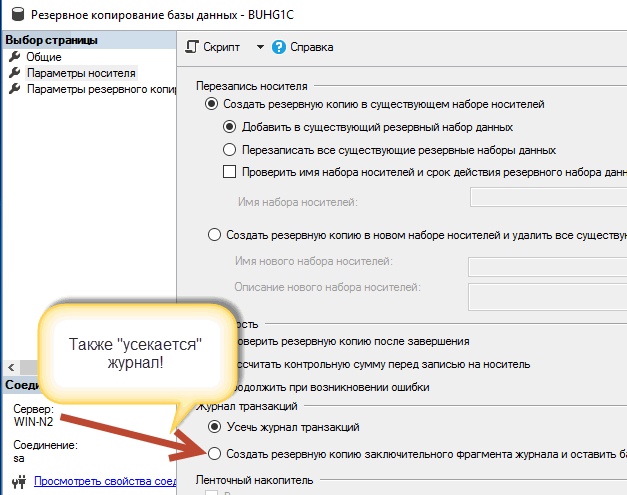
Вывод:
В «полной» модели восстановления бэкап журналов транзакций НЕОБХОДИМ! Если Вы не хотите в один прекрасный день обнаружить, что свободное место на диске, где он находится, уже закончилось!
Если ЛОГ уже вырос ?
Конечно, если Вы раньше не делали бэкапов журналов, лог соответственно вырос, то здесь одним бэкапом журналов транзакций не обойтись!
И вот почему:
При бэкапе журналов происходит только его «усечение», а при «усечении» высвобождается только пространство внутри файла, а нам нужно еще и его размер на диске освободить.
Какой вид у нашего лога после его бэкапа (если он уже вырос) смотрите рис. ниже.
¶ Почему растет LOG в MS SQL ?
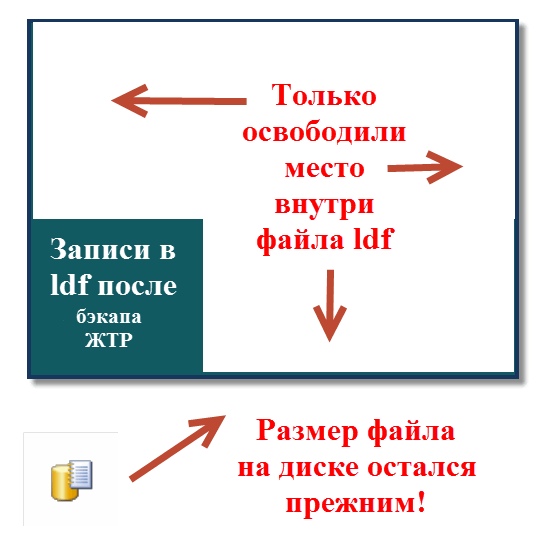
Образно говоря “рамки раздвинуты” намного больше самого файла ldf, так как раньше мы не делали бэкап журналов, и поздно выполнив такой бэкап, мы сократили только его содержимое внутри, оставили только его активную часть (неактивная уже находится в бэкапе ЖТР), а размер при этом на диске остался прежний! Конечно при регулярном бэкапе ЖТР он бы не вырос (обычно не растет) до огромных размеров, и никакие другие действия бы не требовались!
Только сам бэкап ЖТР!
Следовательно в нашем “запущенном” случаи нужно выполнить уже две операции:
- «Усечение» – он же бэкап ЖТР
- «Сжатие» – DBCC SHRINKFILE (или визуально в SSMS используя «Сжатие»).
¶ Почему растет LOG в MS SQL ?
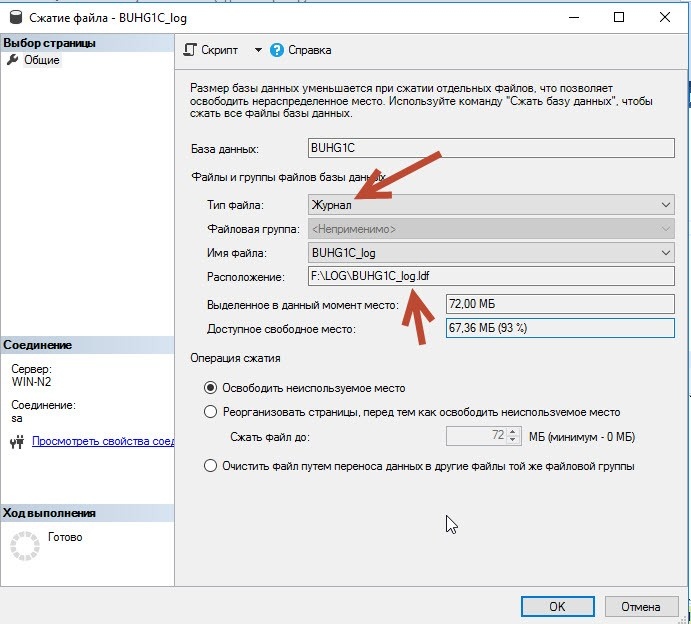
Полный пример скрипта для «Усечения и Сжатия» ЛОГА:
USE [BUHG_1S]
BACKUP LOG [BUHG_1S] TO DISK='NULL'
go
DBCC SHRINKFILE ([BUHG_1S_log], 1)
go
Скрипт выполнит сперва бэкап и затем сжатие журнала LDF!
Копия журнала будет создана на диске (по умолчанию для бэкапа) с именем NULL!
ВНИМАНИЕ!
Все делаем в строгой последовательности: Шаг «1» и только после шаг «2»!
То-есть сперва «усекаем» журнал, создав бэкап ЖТР и только затем его «сжимаем», если сделать наоборот, тогда потеряете все возможности восстановится, используя данные из журнала, их там просто уже не будет!
Если бэкап и сжатие ничего не дают, или не выполняются эти команды!
Бывают случаи, когда ничего из выше перечисленного не помогает (к сожалению иногда и такое бывает при ошибках в логе, открытых транзакциях, «битый лог» и тд.).
Что можно предпринять ?
- Сделать бэкап «Полный» базы (потом удалить базу и лог) и заново создать базу и восстановится уже из этого «полного» бэкапа.
- Провести небольшую диагностику, выполнив скрипт:
select log_reuse_wait, log_reuse_wait_desc from sys.databases where name = 'BUHG_1S'
После его выполнения мы получим один из ниже приведенных вариантов:
- Вариант 1. Если «пусто» – это означает что лог можно прямо сейчас сократить, и затем еще раз применить «Shrink» Сжатие!
- Вариант 2. Если видим Log_Backup – это говорит о том, что Backup Log не выполнено, или выполнено некорректно! Все нормально, можно просто попытается повторно сделать бэкап лога.
- Вариант 3. Если получили Replication – значит, что лог не обрезается из-за репликации – скорее всего, просто есть ошибки. (В 1С такое редко встречается).
Но если Ваш случай, тогда вот эту команду нужно выполнить:
sp_removedbreplication '[BASE_1S]'
После ее выполнения можно попытаться повторно сделать бэкап и сжатие лога.
- Вариант 4. Он же и самый распространённый: Active transactions – означает, что в базе есть “подвисшие” транзакции.
Вот собственно с этими «зависшими» или как их называет MS SQL «активными открытыми» транзакциями нам нужно справиться!
И так сперва выполним DBCC OPENTRAN (чтоб найти эту транзакцию).
Находим эту «открытую» транзакцию и просто удалим ее! (Но не спешите это делать прямо сейчас!)
Transaction information for database ‘master’.
Oldest active transaction:
SPID (server process ID) : 24
UID (user ID) : -1
Name : user_transaction
LSN : (255:4351:1)
Start time : Jun 6 2019 15:25:07:303PM
SID : 0x050400000000000515000000a065cf7e78sdf55gs4g47c877sdgsdg4564dsg4
DBCC execution completed. If DBCC printed error messages, contact your system administrator.
Из всего этого, что выдал MS SQL нам нужно только Start, time и SPID.
Если транзакция в базе 1С выполняется больше нескольких секунд, это уже означает что что-то не так. А если start Time будет, к примеру, 10-20 или более от текущего времени, тогда такие транзакции (иногда) стоит завершить «руками»!
Для завершения процесса (транзакции) вводим команду: KILL [Process ID]
Где Process ID равно SPID, тесть 24 как в нашем случаи!
При этом незавершенные транзакции откатятся средствами самого MS SQL Server.
ВНИМАНИЕ!
При этом могут завершится некоторые сеансы пользователей, а также могут произойти и другие нежелательные действия, если Вы не понимаете, что это была за транзакция и на что она влияет!
И вот здесь стоит «копнуть глубже» и узнать все подробности о ней!
Выполним скрипт:
DBCC OPENTRAN
DECLARE @sqltext VARBINARY(128)
SELECT @sqltext = sql_handle
FROM sys.sysprocesses
WHERE spid = 24
SELECT TEXT
FROM sys.dm_exec_sql_text(@sqltext)
GO
Уточним что:
WHERE spid = 24
- “24” – это наш Process ID который мы узнали выполнив еще первый скрипт!
DBCC OPENTRAN
В результате его работы получим текст команды SQL Server, на которой и повисла транзакция.
Из неё нам нужна будет таблица в которую производилась запись, далее используя функцию “ПолучитьСтруктуруХраненияБазыДанных()” вы определите таблицу в терминах объектов метаданных в которую производилась запись и смотрите код.
Обычно, такие проблемы случаются из-за:
- Ошибки в сетевых подключениях для толстого клиента, в сетевых подключениях клиентов, для тонкого – только в проблемах сети между сервером 1С и MS SQL.
- В неправильных действиях записи в файл, запуск внешних обработок, чтения из файла производимых в транзакциях (при записи, при проведении, при перепровидении)
- Если нашли эти проблемы, тогда конечно их на уровне самой 1С и нужно исправить!
- Еще транзакция может быть «системная», тогда стоит проверить наличие включенных механизмов типа «лог-шиппинг».
- Банально, но иногда (если есть возможность) конечно, помогает даже обычный перезапуск MS SQL!
Ну вот собственно и все, Ваш лог всегда будет в порядке!
Неверные методы борьбы с растущим логом
Чтоб лучше понять бессмысленность некоторых подходов в этой битве «Распухшего лога», нужно их предварительно осознать, чтоб в будущем не допускать.
DBCC SHRINKFILE – «шринкование или шринк» лога.
Большинство пользователей вместо того, чтоб настроить бэкап журналов транзакций, постоянно занимаются его усечением, используя DBCC SHRINKFILE.
Команда «сжимает» файл лог, действительно уменьшается в размерах, теряя тем самым, весь смысл «полной» модели восстановления, так как после “шринка” лога фактически нет, и восстановиться можно только если есть бэкап. Операцию приходится часто повторять, так как лог конечно без бэкапа самого лога, продолжает расти.